Reasoning Implicit Sentiment with Chain-of-Thought Prompting
用思想链提示推理隐式情感
摘要
虽然情感分析系统试图根据输入文本中的关键观点表达来确定给定目标的情感极性,但在隐式情感分析(ISA)中,观点线索是以隐式和模糊的方式出现的。因此,检测隐式情感需要常识和多跳的推理能力来推断观点的潜在意图。受最近的思想链(CoT)思想的启发,在这项工作中,我们引入了三跳推理(THOR) CoT框架来模拟ISA的类人推理过程。我们设计了THOR的三步提示原则,一步一步地诱导出隐含的方面、观点,最后是情感极性。我们的THOR + Flan-T5 (11B)在有监督的情况下将最新的SoTA(state-of-the-art)推进了超过6 %的F1。更引人注目的是,THOR+GPT3(175B)在零样本下将SoTA提升了50 %以上的F1。我们的代码公开在 https://github.com/scofield7419/THOR-ISA 。
1. 引言
情感分析( SA )旨在根据输入文本检测对给定目标的情感极性。SA可以分为显式SA ( ESA )和隐式SA ( ISA ),其中前者是当前的主流任务,其情感表达显式地出现在文本( Pontiki et al , 2014)中。与ESA不同,ISA更具有挑战性,因为ISA中的输入只包含事实描述,而没有直接给出( Russo et al , 2015)的显式意见表达。例如,给定一个没有显著线索词的文本'Try the tandoori salmon! ',几乎所有现有的情感分类器都对'the tandoori salmon'预测中性极性。人类可以很容易地准确地判断文本的情感状态,因为我们总能把握文本背后的真实意图或观点。因此,如果不真正理解情绪是如何被唤起的,传统的SA方法对ISA是无效的。
事实上,首先发现隐藏的意见情境对于实现准确的ISA是至关重要的。对于图1中的显性案例# 1,它不容易捕捉到整体的情感图片(例如, "环境"是方面, "伟大"是意见),因此可以精确地推断对给定目标酒店的正极性。受这种细粒度情感精神(薛峰、李晓萍, 2018 ;张杰等, 2021 ; Xu et al , 2020)的启发,我们考虑挖掘隐含的方面和观点状态。对于图1中的隐式情况#2,如果一个模型可以首先推断关键的情感成分,例如,潜在的方面"味道",潜在的意见"好的和值得尝试",那么最终极性的推断可以大大缓解。为了达到这个目标,常识推理(也就是说,推断什么是'tandoori salmon')和多跳推理(即,先推断出方面,然后再推断出意见)的能力是必不可少的。
幸运的是,最近预训练大规模语言模型( LLMs )的巨大成功提供了一个很有前途的解决方案。一方面,LLMs被发现携带着非常丰富的世界知识,表现出非凡的常识理解能力( Paranjape et al , 2021 ; Liu et al , 2022)。另一方面,最新的思维链( CoT )思想揭示了LMs的多跳推理( Wei et al . , 2022 ; Zhou et al , 2022 ;张杰等, 2023)的巨大潜力,其中带有一些提示的LLM可以出色地进行链式推理。在所有这些成功的基础上,本文实现了一个面向ISA的三跳推理CoT框架( THOR )。在LLM的基础上,我们设计了3个提示语进行3步推理,每个提示语分别推断1 )给定目标的细粒度方面,2 )对该方面的潜在观点,3 )最终的极性。通过这种由易到难的增量推理,可以一步一步地引出整体情感图片的隐藏上下文,从而更容易地实现最终极性的预测,有效地缓解了任务预测的困难。
为了保证每个推理步骤的正确性,我们考虑了一种基于Wang等人( 2022b )启发的CoT自一致性机制,即选择具有推断方面和观点的高投票一致性的候选答案(在每一步中)。对于有监督的微调设置,我们进一步提出了一种推理修正方法。我们使用中间推理答案作为模型输入来预测最终的标签,其中来自黄金标签的监督将教导LLM产生更正确的推理。在有监督的微调设置下,我们的基于Flan - T5的THOR在F1得分上将当前最好的基线提高了6 %以上,并且在零样本设置下,这种差距被进一步放大。最引人注目的是,我们基于GPT3的175B参数的THOR将基线提高到了F1得分的51.10 %。
综上所述,这项工作为隐式情感检测贡献了一种多跳推理解决方案,有助于实现对传统非推理方法的显著改进。据我们所知,这是将CoT思想成功扩展到情感分析领域的首次尝试。我们的方法简单而有效,可以广泛地应用到其他类似的NLP问题中,而无需付出太多的努力。
2. Three-Hop推理框架
SA (无论是ESA还是ISA)的任务定义为:给定一个带有目标项 的句子 ,模型确定对 的情感极性 ,即积极、中性或消极。我们使用带有提示的现成LLM来解决任务。对于标准的基于提示的方法,我们可以构造如下的提示模板作为LLM的输入:
给定句子X,对t的情感极性是什么?
LLM应通过返回答案。
2.1 思维链提示
现在考虑CoT式提示( Wei et al . , 2022 ; Fu et al , 2022)方法进行多步推理。在我们的THOR( cf.图2)中,我们并不是直接询问LLM关于 的最终结果,而是希望LLM在回答 的最终结果之前推断潜在的方面和观点信息。这里我们定义了中间方面项 和潜在意见表达 。我们构造three-hop提示如下。
步骤1。我们首先询问LLM在下面的模板中提到了 的哪些方面:
C1[给定的句子X],t 的哪个具体方面可能被提及?
是第一个hop的提示上下文。这个步骤可以表述为 ,其中 是输出文本,明确提到了方面 。
步骤2。现在基于 , 和 ,我们要求LLM详细回答关于 的潜在观点是什么:
C2[ C1 , A]。基于常识,对于t的上述方面,隐含的看法是什么,以及为什么?
是连接 和 的第二个hop提示语境,这一步可以写成 ,其中 是包含可能意见表达 的答案文本。
步骤3。以完整的情感骨架( X , t , a和o)为上下文,最后请LLM推理出极性t的最终答案:
C3[ C2 , O]。基于这种观点,什么是对t的情感极性?
为第三提示语境。记这一步为 ( y_\hat = argmaxp( y | X , t , a , o) ) 。
2. 通过自洽增强推理
我们进一步利用自洽机制( Wang et al. , 2022b ; Li et al., 2022b)来巩固推理的正确性。具体来说,对于3个推理步骤中的每一个步骤,我们设置LLM解码器来生成多个答案,每个答案都可能给出方面 、观点 和极性 的不同预测。在每一步中,保留那些推断 , 或 的投票一致性高的答案。我们选择置信度最高的那个作为下一步的上下文。
2.3 有监督的推理修正
我们还可以在按需训练集可用的情况下对THOR进行微调,即有监督的微调设置。我们设计了一种推理修正方法。技术上,在每个步骤中,我们通过连接 1)初始上下文,2)本步骤的推理答案文本和 3)最终问题来构建提示,并将其输入LLM来预测情感标签,而不是去进行下一步的推理。例如,在步骤-1的最后,我们可以组装一个提示:[ C1 , A , "对t的情感极性是什么? "]。在金标签的监督中,LLM会被教导产生更多正确的中间推理,有助于最终的预测。
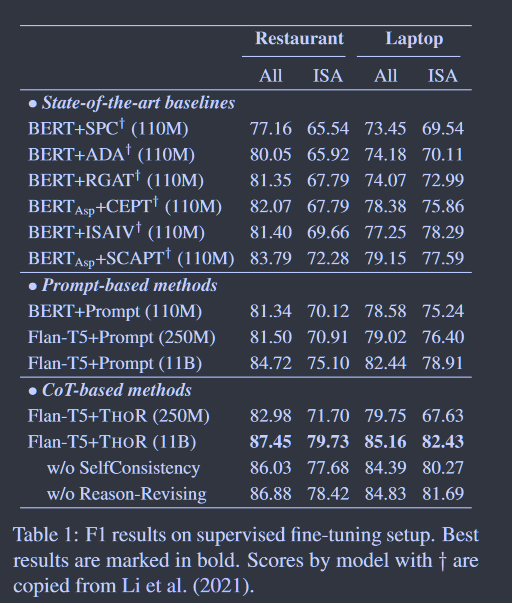 表1:有监督微调设置下的F1结果。最好的结果用粗体标出。表1中带"的模型得分复制自Li et al. ( 2021 )。
表1:有监督微调设置下的F1结果。最好的结果用粗体标出。表1中带"的模型得分复制自Li et al. ( 2021 )。
3. 实验
设置 我们在基准的Sem Eval14 Laptop和Restaurant数据集( Pontiki et al , 2014)上进行实验,其中所有的实例都按照Li等( 2021 )的方法分为显式情感和隐式情感。由于编码器风格的BERT不能生成支持CoT的文本,我们使用编码器-解码器风格的FlanT52作为我们的主干LLM。我们还用GPT3 (布朗等, 2020)和ChatGPT ( Ouyang et al , 2022)进行了测试。我们使用了Flan - T5的四个版本:250M ( base ),780M ( large ),3B ( xl )和11B ( xxl ),以及GPT3的四个版本:350M,1.3B,6.7 B和175B。注意,GPT3没有发布模型参数,我们通过API以提示的方式使用。这也意味着我们无法用GPT3进行有监督的微调。我们与目前表现最好的基线进行了比较,包括:BERT + SPC ( Devlin et al , 2019),BERT + ADA ( Rietzler et al , 2020),BERT + RGAT ( Wang et al , 2020),BERTAsp + CEPT ( Li et al , 2021),BERT + ISAIV ( Wang et al , 2022a)和BERTAsp + SCAPT ( Li et al , 2021)。我们同时考虑有监督的微调和零样本设置。我们采用F1作为评价指标。在小样本设置下,我们通过它们的源代码重新实现了基线。我们的实验在4块NVIDIA A100 GPU上进行。
 表2:零样本学习设定的模型结果。我们重新实现了零样本性能的最先进的基线。" ZeroCoT '表示用零样本学习CoT提示LLM,'让我们一步一步思考' (Brown 等, 2020)。
表2:零样本学习设定的模型结果。我们重新实现了零样本性能的最先进的基线。" ZeroCoT '表示用零样本学习CoT提示LLM,'让我们一步一步思考' (Brown 等, 2020)。
有监督的Fine-Tuning结果 比较结果见表1。有趣的是,快速学习的BERT性能低于SoTA基线BERTAsp+SCAPT,即使是双参数的Flan-T5-base(250M)也未能战胜SoTA。BERTAsp + SCAPT在大规模情感方面感知标注数据上进行预训练,在SA上表现出较强的能力。但在我们的THORCoT提示下,Flan-T5-base明显优于SoTA。进一步,当使用较大的LLM,即11B参数时,我们可以发现基于香草提示的FlanT5超过了最佳基线。更值得注意的是,Flan-T5-11B搭配THOR对ISA有显著提升,Restaurant上提升7.45%(=79.73~72.28),Laptop上提升5.84%(=82.43~77.59),平均提升6.65%(7.45+5.84)/2 F1。此外,自我一致性和推理修正机制的消融也表明了它们在THOR方法中的重要性。
零样本推理的结果 在表2中,我们比较了零样本的表现。我们可以发现,与当前的SoTA基线相比,基于提示和基于CoT的方法的改进都显著增加。但总的来说,基于CoT的方法和我们的THOR在ISA上显示出更显著的改进。例如,我们的Flan-T5-11B THOR系统在两个数据集上比性能最好的基线(BERTAsp+SCAPT)的F1值平均提高了30 %以上。最引人注目的是,当THOR装备于超大型LLM,即GPT3-175B时,我们可以观察到令人印象深刻的改善,接近Flan-T5-11B THOR在监督环境下的水平,如表1所示。具体而言,在Restaurant和Laptop上分别提升了51.94%(=81.96~30.02 )和50.27%(=76.04~25.77 )的SoTA结果,平均51.10%(51.94+50.27)/2个F1跳跃。
不同模型尺寸对Llms的影响 在表1和表2中,我们看到了使用(非常)大LLM的功效。在图3中,我们研究了不同LLM尺度的影响。我们看到,随着模型规模的增大,我们的多跳推理提示的功效呈指数级放大。这与已有的CoT提示方法( Wei et al . , 2022 ; Zhou et al , 2022 ; Fu et al , 2022)的发现非常吻合,即LM越大,CoT的改善效果越显著。因为当LLM足够大时,常识推理和多跳推理的能力得到了极大的发展和加强。
用Thor改进Chatgpt ChatGPT的最新诞生带来了NLP和AI社区的革命性进步。在这里,我们比较了我们的THOR on GPT3 (175B)和ChatGPT的改进。图4给出了100个测试实例的测试结果。我们可以看到,两种LM在ESA上都表现出了非常高的性能,而THOR的增强效果非常有限。但是,基于提示的GPT3和ChatGPT在ISA上仍然失败很多,而我们的THOR在ISA上有了很大的改进。
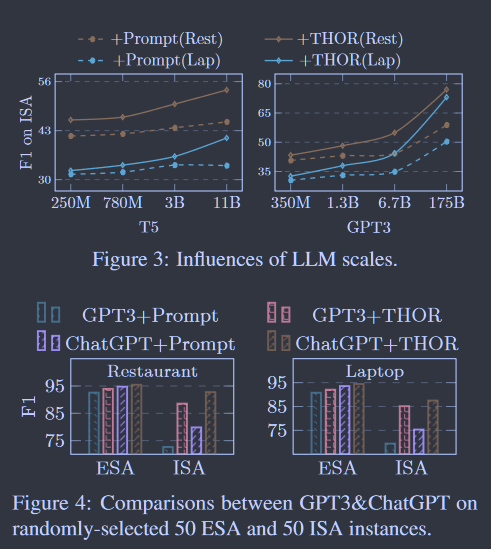
图3:Llm标度的影响。图4:Gpt3和Chatgpt在随机选取的50个Esa和50个ISA实例上的比较。
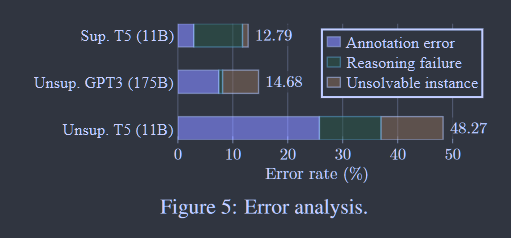 图5:误差分析。
图5:误差分析。
故障分析 在图5中,我们展示了使用THOR时失败案例的错误率,其中我们总结了三种错误类型。Flan-T5-11B LLM在零样本下的错误率为48.27 %,而在有监督微调下的错误率为12.79 %。无监督的GPT3 (175B)与有监督的T5具有相似的低错误率,而有监督的T5由于无法推理而失败的次数较多。与Supervised-T5相比,无监督GPT3的大部分错误来自于有问题的数据标注。由于Supervised-T5对"假"标签的监督进行了微调,因此它实际上可以学习到虚假的相关性,但具有更高的测试精度。
4. 相关工作
情感分析长期以来一直是NLP社区( Pang和Lee , 2007 ; Dong et al . , 2014 ;施炳展等, 2022)的研究热点。虽然显式SA模型可以轻松地根据意见表达进行预测,但是由于隐式意见特征( Li et al , 2021 ; Wang et al , 2022a)的存在,使得隐式SA变得更加棘手。和在现实场景中,ISA往往更为普遍。尽管已经对ISA ( Li et al , 2021 ; Wang et al , 2022a)做出了努力,但现有的工作仍然可以局限于传统的推理范式。如前所述,ISA应该通过推理来解决,即常识和多跳推理。因此,本工作遵循这种直觉,以多跳推理机制解决ISA为目标。
作为SA的一个关键分支,细粒度SA已经得到了很好的探索( Wang et al. , 2017; Li et al, 201, 2022a)。细粒度情感分析的思想是将情感分析分解成若干个关键的情感要素,包括目标、方面、观点和情感极性,它们在细节( Peng et al. , 2020;Fei 等, 2022)上共同构成完整的情感图。这项工作吸取了同样的细粒度SA的精神。我们认为隐式情感的推理应该是一个渐进的过程,一步一步地推断出情感元素,最终以由易到难的方式理解情感极性。
语言模型预训练在增强下游应用(Raffel et al, 2020)的实用性方面受到了越来越多的研究关注。最近,大规模语言模型(LLMs)在人类智能方面表现出了巨大的潜力,例如ChatGPT (Ouyang et al, 2022)。LLMs已被广泛证明在常识理解(Paranjape et al, 2021;Liu et al,2022)和多跳推理(Wei et al.,2022;Zhou et al, 2022)上表现出非凡的能力。本文基于最新提出的思想链( CoT )思想,实现了基于LMs的隐式情感推理。CoT提示是一种无梯度的技术,它诱导大的LM产生中间推理步骤,从而得出最终的答案。Wei等人( 2022 )正式研究了语言模型中的CoT提示,他们诱导LM产生一系列连贯的中间推理步骤,这些步骤直接指向原始问题的最终答案。
5. 结论
在本文中,我们提出了一个three-hop推理提示框架来实现隐式情感分析的思维链推理过程。基于现有的LLM,我们设计了三个提示进行三个步骤的推理,每个步骤分别推断细粒度方面、潜在观点和最终极性。在ISA数据集上,配备我们THOR的不同LLM在有监督和零样本设置上都表现出了比现有最好的基线更好的性能。我们表明,LLMs越大,我们的THOR方法的改进越显著。
局限性
THOR只有在集成到足够大的模型中时才有助于释放LLMs的全部能量,而在中等或较小尺寸的LLMs上,由于LLMs的涌现性,THOR的提升会受到一定程度的限制。



